Что такое Google Dorks? Дублированный контент. Какие причины и решения
Представьте, что вы получили возможность собирать и анализировать маркетинговые идеи конкурентов, не проводя полноценный аудит их сайтов. Разве не здорово? Просто подумайте, какие возможности это откроет для вашего интернет-маркетинга и продвижения в сети. Зная «козыри» в рукавах конкурентов, вы сможете создавать более релевантный контент, получать больше органического трафика и повышать конверсии.
Звучит неплохо, не так ли? Тогда внимание — предлагаем секретное оружие, позволяющее подсмотреть идеи конкурентов за считанные секунды. Это оружие на 100% бесплатно — любой игрок на рынке может его применить. Вы наверняка знаете, о чем речь. И наверняка используете эту платформу каждый день. Потому, что секретное оружие, о котором мы говорим — это операторы .
Что такое операторы поиска?
Операторы поиска Google — это команды и символы, которые ограничивают или расширяют пространство вашего поиска. Они могут использоваться практически для любых целей, включая исследования конкурентов. Если ваши конкуренты не настолько известны, чтобы сразу появляться наверху выдачи, то традиционный поиск будет не слишком полезен — много времени уйдет на скроллинг результатов.
Когда пространство поиска нужно ограничить, вам помогут поисковые операторы. Они пригодятся для SEO, контент-маркетинга и многих других сфер. И, в отличие от специализированных программ и утилит, поисковые операторы доступны каждому прямо в строке поисковой системы.
Представим, что вы — небольшая веб-студия, которая помогает маркетологам и планирует оказывать услуги по работе с дешевыми или бесплатными DIY-сервисами, наподобие Canva. Как быстро изучить их контент, маркетинговые стратегии и аудиторию?
Анализ всего сайта — неподъемная задача. Конечно, можно просто ввести в поиск «конкуренты Canva». Но объем выдачи по такому запросу невозможно проанализировать тщательно:
Вы получите слишком много результатов — 221 000 ссылок, если быть точным. Вам предстоит часами скроллить их ряды, чтобы найти нужную вам информацию. Как сразу получить выжимку самых релевантных сайтов по запросу? Здесь вам и помогут операторы поиска.
Если сомневаетесь — используйте цепи команд
Поисковые операторы могут быть сложными в использовании. Иногда, чтобы прийти к цели, проще добавить один или два дополнительных оператора.
Цепи команд позволяют использовать несколько поисковых операторов для улучшения результатов выдачи. Каким бы способом вы их ни применяли, цепочки поисковых операторов помогут вам быстрее получить нужные данные.
А теперь — поехали.
Команда 1: site:
site: — это базовая команда, которая запустит поиск по сайту конкурента. Команда ограничивает результаты поиска пределами одного сайта, что сделает выдачу релевантнее. Скажем, мы исследуем сайт инструмента Canva и хотим проанализировать его страницы. Мы можем пойти прямо на ресурс и изучать его вручную, но это займет время.
Другой вариант — ввести в Google команду «site:canva.com/ru_ru». Вот, что вы получите в результате:

Обратите внимание, что все результаты — только с нужного нам сайта. Вам не придется скроллить рекламу, статьи, ветки на форумах и прочую информацию на сторонних ресурсах. Вы получили краткий перечень страниц одного сайта. Быстро просмотрев этот список, вы сможете найти идеи для собственных проектов.
Но в примере выше есть один недостаток: мы сузили поиск до одного сайта, но выдача все еще довольно объемная. Нужно добавить к запросу еще несколько условий. Представим, что ваша компания делает особенный акцент на создании инфографики. В таком случае, просто добавьте запрос «создать инфографику» после оператора site: и адреса сайта. Вот как это выглядит: «site:canva.com создать инфографику».

В результате, вы получите куда меньше ссылок. В нашем примере, поисковая система выдала всего 21 страницу. Теперь вы сможете изучить материалы, релевантные вашим бизнес-интересам.

Строго говоря, задав поисковый запрос «Canva» и «инфографику», вы пришли бы к тем же результатам. Но вам пришлось бы преодолеть десятки и десятки нерелевантных страниц. Вот почему так полезен оператор site:. Он значительно сужает поиск и помогает быстрее получить нужную информацию.
Команда 2: intitle: или allintitle:
Рассмотрим две команды, которые выполняют примерно одну функцию. Поисковые операторы intitle: и allintitle: выполняют поиск по страницам, в поле «title» которых указаны выбранные вами условия поиска. Эти операторы отлично подходят для поиска точных фраз в заголовках страниц, статей или лендингов.
Предположим, вы запускаете поиск по фразе «шаблоны для инфографики»:


Так-то лучше — всего 52 700 страниц. Но проблема в том, что и такая выдача недостаточно узка. И, если вы заметили, сейчас команда воспринимает только первое слово запроса — «шаблоны». Слегка переформулируем и включим весь запрос в поиск.

Теперь мы имеем 3300 страниц — большой прогресс! Тот же результат мы получили бы, задав команду «allintitle:шаблоны инфографики» вместо громоздкого «intitle:шаблоны intitle:инфографики». Оператор allintitle: ищет по заголовкам страниц всю фразу целиком.
Итак, мы отмели 99% нерелевантных сайтов и теперь можем спокойно изучить наиболее интересные нам результаты. Но выдачу можно сузить еще больше — если добавить оператор site:. Например: «allintitle:шаблоны инфографики site:canva.com/ru_ru». Совмещение двух операторов позволит сузить объем выдачи буквально до нескольких ссылок.
Это позволит получить предельно конкретные и релевантные материалы на интересующую вас тему.
Команда 3: intext: или allintext:
Операторы intext: или allintext: также позволяют найти слово или фразу, но только в основном тексте страницы, а не в заголовке. Оператор allintext:, как и оператор allintitle:, ищет фразы целиком, избавляя нас от необходимости предварять каждое слово командой intext:.
Эти команды дают еще более глубокое видение контента конкурентов. Это особенно полезно в исследовании SEO-стратегии их сайтов и изучении того, как поисковики классифицируют их страницы.

Теперь результаты поиска полностью основаны на конкретных словах и фразах. Но мы продолжаем сужать поле поиска и возвращаемся к оператору site:, так как нас интересует контент определенного сайта:

Мы снова получили небольшую выдачу — всего 34 результата. Теперь все, что от вас требуется — выбрать лучшие статьи, прочесть их и позаимствовать у конкурента наиболее прибыльные идеи.
Команда 4: Точный поиск с кавычками
Еще один метод поиска точных совпадений по слову или фразе. Эта команда особенно полезна для исследования ключевых выражений на сайте конкурента.
Заключая запрос в кавычки, вы найдете точные совпадения — в отличие от обычной выдачи. Посмотрим, как это работает, на примере фразы «инфографика маркетологам».


Итак, сервис не продвигается непосредственно по данному ключевому слову. С одной стороны, это плохо — мы не сможем узнать, как Canva работает с этой аудиторией. С другой стороны, у нас появляется шанс предложить аудитории, не охваченной маркетингом Canva, собственное решение. Как думаете, вы пришли бы к такой бизнес-идее, не владея техниками «умного» поиска?
Команда 5: исключить слова (-) или добавить слова (+)
Иногда в процессе конкурентного анализа вам потребуется исключить или добавить определенные выражения, чтобы получить нужные результаты. В таких случаях используйте символы (-) или (+) для добавления или удаления определенных слов из поиска.
Например, вам нужно найти информацию об инфографике, но вы не хотите видеть слишком много примеров. Тогда исключим из выдачи слово «примеры» и вот, что получим:

Мы получили множество ссылок на ресурсы об инфографике, с конкретными советами и руководствами, но без надоедливых примеров.
Как вы уже догадались, знак (+), напротив, включает слово в поиск. Используем его, чтобы найти инфографику о контент-маркетинге. Вот основной поиск:


Команда 6: Related:
Последний поисковой оператор в этой подборке выдает сайты, похожие на домен заданного ресурса. После того как вы изучили сайт основного конкурента, вы можете проверить, кто еще проявляет активность на вашем рынке. Так проще будет избежать совпадений и выделиться среди похожих офферов. Вернемся к инструменту Canva и посмотрим, сможет ли Google найти сайты со схожей моделью?

Всего 9 результатов! Так вы получили дополнительный список ресурсов, которые стоит исследовать в будущем.
Заключение
Если вы встали в тупик, разрабатывая стратегию digital-маркетинга, просто подсмотрите, что делают ваши конкуренты. Но традиционные методы поиска могут не дать быстрых результатов. Поэтому научитесь «гуглить» как профессионал — с помощью поисковых операторов. Эти команды позволят фильтровать выдачу по сайту, заголовку, тексту и даже находить сайты, похожие на ресурс конкурента. Так вы сократите область поиска от миллионов ссылок до нескольких десятков наиболее важных страниц.
Что делать, когда вы проанализировали конкурентов, составили «семантическое ядро» из наиболее перспективных ключевых слов и готовы запустить капманию? Не забудьте , чтобы принять на него целевой поток входящего трафика.
Часто на сайтах можно встретить версию для печати той или иной страницы . Многие думают, что это что-то встроенное в сам браузер или что это делается очень просто. На самом деле, это совсем не так. Версия для печати - это обычная страница , которую Вам нужно самостоятельно сделать.
Вы можете посмотреть на версию для печати у этой статьи. Фактически, что нужно отображать там? Название статьи, раздел, категория, автор, сам текст и дата. Всё это и выведено на эту страницу. Нужны ли меню, форма поиска, различные блоки? Не думаю, поэтому их и нет.
Так же убедитесь, что ширина версии для печати не превосходит 650px , иначе браузер может порезать края.
Итак, Вы уже поняли, что версию для печати Вам надо создавать самостоятельно, выводя ровно то, что нужно пользователю. Теперь о том, как это сделать.
Есть 2 варианта : создать отдельную страницу и создать отдельный файл стилей. Первый вариант, думаю, понятен. Создаёте ещё одну страницу с версией для печати и на основной странице даёте ссылку на эту печатную версию. Пользователь по ней переходит и через "Файл"->"Печать" он её распечатает.
Второй вариант подразумевает создание отдельной таблицы стилей, где Вы скроете все лишние блоки (через display: none; ) и поставите соответствующие размеры у выводимого контента. Дальше такой файл стилей подключается следующим образом:
Теперь если пользователь захочет распечатать эту страницу, то распечатается не то, что он видит, а то, что прописано в print.css . Фактически, пользователь видит страницу в одном виде, а принтер в совсем другом.
Вот таким образом создаётся версия для печати любой страницы сайта.
Это устранение ошибок под названием «дубли контента». Дублирующийся контент означает, что подобный контент отображается в нескольких местах (URL-адресах) в интернете. В результате поисковые системы не знают, какой URL показывать в результатах поиска. Это может навредить ранжированию веб-страницы сайта. Проблема становится серьезней, когда люди начинают ссылаться на разные версии контента. В этой статье мы расскажем о причинах дублирования контента и найдем решения для каждой из них.
Представьте себе, что вы находитесь на перекрестке, а дорожные знаки указывают по двум разным направлениям на один и тот же конечный пункт назначения: какую дорогу вы должны выбрать? И если пойти по «худшему» направлению, конец пути также может слегка измениться. Как читателю, вам всё равно: вы получили контент, к которому стремились. Но поисковая система должна выбрать, какой из них показывать в результатах поиска, так как она не должна показывать один и тот же контент дважды.
Допустим, ваша статья о «ключевом слове x» появляется на http://www.example.com/keyword-x/ и точно такой же контент появляется на http://www.example.com/article-category/keyword-x/. Это происходит во многих современных системах управления контентом (СМS). Ваша статья была поднята несколькими блоггерами, одни из которых сослались на первый URL, другие сослались на второй URL. Этот дублирующийся контент - проблема для вашего интернет-ресурса, так как ссылки одновременно рекламируют разные URL-адреса. Если бы все они ссылались на один и тот же URL-адрес, ваш рейтинг в топ-10 для «ключевого слова x» был бы намного выше.
1. Причины дублирующегося контента
Есть уйма причин, которые вызывают дублирование контента. Большинство из них являются техническими: не так уж часто человек решает разместить один и тот же контент в двух разных местах, не выделяя исходный источник. Тем не менее, технические причины многочисленны. Это происходит в основном потому, что разработчики не думают как браузер или пользователь, не говоря уже о паутине поисковых систем, они думают как разработчик. А как же вышеупомянутая статья, которая появляется на http://www.example.com/keyword-x/ и http://www.example.com/article-category/keyword-x/? Если вы спросите разработчика, он скажет, что она одна.
Давайте посмотрим, как выявить наличие дублирующегося контента на вашем веб-сайте, а также объясним его причину и сделаем всё возможное для его устранения.
1.1.Непонимание смысла URL-адресов
Разработчик просто разговаривает на другом языке. Вы видите, что весь сайт, вероятно, снабжен системой баз данных. В этой базе данных есть только одна статья, программное обеспечение веб-сайта просто позволяет найти одну и ту же статью в базе данных через несколько URL-адресов. Это объясняется тем, что в глазах разработчика уникальный идентификатор для этой статьи - это идентификатор статьи, который есть в базе данных, а не URL. Однако для поисковой системы URL-адрес является уникальным идентификатором части контента. Если вы объясните это разработчику, он увидит проблему. И после прочтения этой статьи вы сможете сразу же предоставить ему её решение.
1.2. Идентификаторы сеансов посетителей
Когда вы отслеживаете посетителей и предоставляете возможность сохранять товары, которые они хотят купить, в корзине покупок, вы даете им сессию. Сессия - это, в основном, краткая история того, что посетитель сделал на вашем сайте, и может содержать такие вещи, как элементы в корзине покупок. Чтобы сохранить сессию посетителя, переходящего с одной страницы на другую, нужно где-то хранить уникальный идентификатор этой сессии, так называемый идентификатор сеанса. Наиболее распространенное решение - сделать это с помощью cookie. Однако поисковые системы обычно не хранят файлы cookie.
Некоторые системы возвращаются к использованию идентификаторов сеанса в URL-адресе. Это означает, что каждая внутренняя ссылка на веб-сайте получает этот идентификатор сеанса, добавленный к URL-адресу, и поскольку этот идентификатор сеанса уникален для этого сеанса, он создает новый URL-адрес и, таким образом, дублирует контент.
1.3. Параметры URL, используемые для отслеживания и сортировки
Другой причиной дублирования контента является использование параметров URL-адресов, которые не изменяют контент страницы, например, в ссылках отслеживания. Вы видите, http://www.example.com/keyword-x/ и http://www.example.com/keyword-x/?source=rss - это на самом деле не один и тот же URL для поисковой системы. Последний может позволить вам отслеживать, из каких источников зашли посетители, но это может также затруднить вам ранжирование. Очень нежелательный побочный эффект!
Разумеется, это не просто отслеживание параметров, это касается каждого параметра, который вы можете добавить к URL-адресу, который не меняет жизненно важную часть контента. Этот параметр предназначен для «изменения сортировки по набору продуктов» или «показа другой боковой панели»: все они вызывают дублирование содержимого.
1.4. Парсинг и синдикация контента
Большинство причин дублирования контента принадлежат вам самим или, по крайней мере, по вине вашего веб-сайта, когда другие сайты используют ваш контент с вашего согласия или без него. Они не всегда ссылаются на вашу оригинальную статью, и поэтому поисковая система не «получает» ее и приходится иметь дело с еще одной версией той же статьи. Чем популярнее становится ваш сайт, тем больше и чаще вы будете его парсить, расширяя эту проблему все больше и больше.
1.5. Порядок параметров
Другая распространенная причина заключается в том, что CMS не использует красивые и чистые URL-адреса, а скорее URL-адреса, такие как / id = 1 & cat = 2, где ID ссылается на статью, а cat относится к категории. URL /? Cat = 2 & id = 1 будет давать те же результаты в большинстве систем сайта, но они фактически совершенно разные для поисковой системы.
1.6. Пагинация комментариев
В моем любимом WordPress, а также и в некоторых других системах, есть возможность осуществлять пагинацию комментариев. Это приводит к дублированию содержимого по URL-адресу статьи и URL-адресу статьи + / comment-page-1 /, / comment-page-2 / и т. д.
1.7. Версия для печати
Если ваша система управления контентом создает страницы, удобные для печати, и вы связываете их со страницами своих статей, в большинстве случаев Google их найдет, если вы специально их не заблокируете. Какую версию покажет Google? Ту, которая загружена рекламой и периферийным контентом, или ту, которая содержит только вашу статью?
1.8. с WWW и без WWW
Одна из старых ситуаций: домен с WWW и без WWW, дублирующие контент, в случае, когда доступны обе версии вашего сайта. Ещё одна менее распространенная ситуация, которая существует: http и https дублируют контент, когда один и тот же контент передается на оба адреса.
2. Концептуальное решение: «канонический» URL
Как было определено выше, когда несколько URL-адресов ведут к одному и тому же контенту - это является проблемой, но её можно решить. Человек, работающий в одном издании, как правило, сможет легко сказать вам, какой «правильный» URL-адрес для определенной статьи должен быть. Но самое смешное, что иногда, когда вы спрашиваете трёх человек в одной компании, они дают три разных ответа...
Это проблема, которая требует обязательного решения в таких случаях, потому что конечный адрес может быть только один (URL). Этот «правильный» URL-адрес должен быть определен поисковым сервером как канонический URL-адрес.

Ироническое примечание
Канонический - термин, вытекающий из римско-католических традиций, где список священных книг был создан и принят как подлинный. Их окрестили каноническими Евангелиями Нового Завета. А ирония заключается в следующем: Римской Католической церкви потребовалось около 300 лет и многочисленные бои, чтобы придумать этот канонический список, и в конечном итоге они выбрали 4 версии одной и той же истории...
3. Как найти дубли контента?
Возможно, вы не знаете, есть ли у вас дублирующийся контент на вашем сайте. Вот несколько способов, как это выяснить:
3.1. Инструменты Google для веб-мастеров
Инструмент Google для веб-мастеров - отличный инструмент для идентификации дублированного контента. Если вы заходите в Инструменты для веб-мастеров Google для своего сайта, см. Раздел «Вид в поиске» «Оптимизация HTML», и вы увидите следующее:

Проблема в том, что если у вас есть статья, похожая на статью о «ключевом слове X», и она отображается в двух категориях, названия могут быть разными. Они могут быть, например, «Ключевое слово X - Категория X - Пример сайта» и «Ключевое слово X - Категория Y - Пример сайта». Google не будет выбирать эти названия в качестве дубликатов, но вы можете найти их с помощью поиска.
3.2. Поиск заголовков или фрагментов
Существует несколько операторов поиска , которые очень полезны для подобных случаев. Если вы хотите найти все URL-адреса на вашем сайте, которые содержат вашу статью с ключевым словом X, введите в Google следующую поисковую фразу:
Site:example.com intitle:"Ключевое слово X"
Затем Google покажет вам все страницы example.com, содержащие это ключевое слово. Чем конкретнее вы отразите эту часть intitle, тем легче будет отсеять дублированный контент. Вы можете использовать один и тот же метод для идентификации дублированного контента в интернете. Допустим, что полное название вашей статьи было «Ключевое слово X - почему оно классное», вы искали: Intitle: «Ключевое слово X - почему это классно»
Google предоставит вам все сайты, соответствующие этому названию. Иногда стоит поискать одно или два полных предложения из вашей статьи, так как некоторые парсеры могут изменить заголовок.
4. Практические решения по дублированию контента
Когда вы решите, какой URL-адрес является каноническим URL-адресом для вашего контента, вам нужно начать процесс канонизации. Это в основном означает, что мы должны сообщить поисковой системе о канонической версии страницы и позволить ей найти ее как можно скорее.
Существует четыре метода решения, в порядке предпочтения:
- Не создавайте дублирующийся контент;
- Перенаправляйте дубли контента на канонический URL-адрес;
- Добавляйте канонический элемента ссылки на дубликат страницы;
- Добавляйте ссылки HTML с дублированной страницы на каноническую страницу.
4.1. Как избежать дублирования контента?
Некоторые из приведенных выше ошибок при дублировании контента имеют очень простые исправления:
- Используете идентификаторы сеанса в ваших URL-адресах? Их часто можно просто отключить в настройках вашей системы.
- У вас есть дубликаты страниц для печати? Это совершенно не нужно: вам нужно просто использовать таблицу стилей печати.
- Использование пагинации комментариев в WordPress? Эту функцию нужно просто отключить (в настройках «обсуждение») на 99% сайтов.
- Параметры URL в разном порядке? Скажите своему программисту, чтобы он создал скрипт, который позволит использовать параметры в одном порядке.
- Проблемы с отслеживанием ссылок? В большинстве случаев вы можете использовать отслеживание кампаний на основе хеша вместо отслеживания кампаний на основе параметров.
- Две версии сайта с WWW и без WWW? Выберите один вариант и придерживайтесь его, перенаправляя один на другой. Вы также можете отдать предпочтение инструментам Google для веб-мастеров, но вам придется заявлять права на обе версии имени домена.
Если вашу проблему не так легко устранить, возможно, стоит приложить все усилия, чтоб не допускать появления дублирующегося контента. Это, безусловно, лучшее решение проблемы.
4.2. 301 редирект дублированного контента
В некоторых случаях невозможно полностью запретить системе, которую вы используете, создавать неправильные URL-адреса для контента, но иногда их можно перенаправить. Помните об этом во время разговора с разработчиками. Кроме того, если вы вообще избавляетесь от некоторых повторяющихся проблем с контентом, убедитесь, что вы перенаправляете все старые дублированные URL-адреса контента на соответствующие канонические URL-адреса.
4.3. Использование rel = "канонических" линков
Иногда нет возможности избавиться от дублируемой версии статьи, но вы знаете, что это неправильный URL-адрес. Для этой конкретной проблемы поисковые системы ввели элемент канонической ссылки. Он размещен в разделе
вашего сайта и выглядит следующим образом:href="http://example.com/wordpress/seo-
В разделе
Этот процесс немного медленнее, чем 301 редирект, упомянутый Джоном Мюллером от Google, который вы можете сделать, что было бы намного предпочтительнее.
4.4. Возврат к исходному контенту
Если вы не можете выполнить любое из вышеперечисленных действий, возможно, потому, что вы не контролируете раздел
сайта, на котором отображается ваш контент, добавление ссылки на исходную статью сверху или снизу статьи всегда является хорошей идеей. Это может быть то, что вы хотите сделать в своем RSS-канале: добавьте ссылку на статью в ней. Если Google встретит несколько ссылок, указывающих на вашу статью, он вскоре выяснит, что это фактическая каноническая версия статьи.5. Вывод: дублирующийся контент можно исправить, и его необходимо исправить!
Дублирующийся контент встречается повсюду. Это процесс, который вам необходимо постоянно отслеживать. Если вовремя всё исправлять, тогда и вознаграждение будет многочисленное. Ваш качественный контент может взлететь в рейтинге, просто избавляясь от дублирующегося контента на вашем сайте. Конечно, если вам нужна помощь в выявлении этих проблем, помощь вашим разработчикам в поиске решений для устранения проблем с дублирующимся контентом или даже решить эти проблемы для вас, вы всегда можете заказать
Человеческой природе присущ соревновательный дух и желание определить самого лучшего. Составлением винных рейтингов занимаются многие издания и отдельные специалисты.
Авторитетный журнал Wine Spectator составляет ежегодный список ТОП100 по 100-балльной шкале, где Великим классическим винам присваиваются оценки от 96 до 100, а выдающимся - от 90 до 95. Дегустаторы квалифицируют также средние (75-79), хорошие (80-84) и очень хорошие (85-89) вина. Вина с оценкой ниже 75 баллов употреблять не рекомендуется.
Таким образом, общий балл состоит из следующих индивидуальных оценок. Примечание. Поскольку каждый производитель способен производить вино с сияющим внешним видом с помощью красот и фильтров, мы придаем лишь незначительное значение визуальному впечатлению.
Вины, которые не достигают 80 баллов, также описываются, точно оцениваются и играют роль в классификации винодельни, но они не публикуются. Теперь есть разные мнения относительно того, насколько строго эта система должна интерпретироваться. Таким образом, для большинства пользователей этой схемы в течение нескольких лет наблюдается ползучий сдвиг в меток точек, что приводит к неестественному сжатию системы.
Сотня лучших вин по версии журнала Wine Spectator является своеобразным эталоном, с которым сверяются все остальные. Тираж выпуска, публикующего итоговый годовой рейтинг, составляет три миллиона экземпляров!
Знаменитый «американский француз» Роберт Паркер возглавляет команду дегустаторов влиятельного винного рейтинга журнала The Wine Advocate , имеющего более 50 тысяч подписчиков по всему миру. Винный рейтинг «Винного Адвоката» оценивает превосходные вина от 96 до 100 баллов, выдающиеся - от 90 до 95, а очень хорошие - 80-89. Вина ниже 80 баллов считаются средними.
Помните об этом при чтении и использовании нашего руководства, поскольку это важно для понимания отзывов. Каждое вино описано подробно и дает прогноз наилучшего возможного периода питья. Эти данные не соответствуют четкой информации о сроках хранения, а просто предоставляют информацию о периоде, в течение которого вино, скорее всего, будет представлено во время нормального хранения. Год - это всегда ожидание того, что вино представит себя в хорошей форме, по крайней мере, до конца года. Многие вина остаются в хорошей форме далеко за пределами данной даты, но мы не ожидаем, что они будут продолжать развиваться позитивно.
100-балльной шкалы придерживаются винные рейтинги американского журнала Wine Enthusiast , австрийского издания Falstaff Magazine , британского Decanter Magazine , испанского La Guia Penin , интернационального винного гида Стивена Танзера (Stephen Tanzer) International Wine Cellar , а также ежемесячного гида по французским винам La Revue du Vin de France .
Итальянский винный гид Vini d’Italia обозначает лучшие вина рисунком «три бокала», а ресторанный гид Франции Gault & Millau присваивает самым достойным винам 20 баллов из двадцати максимально возможных.
Особенно строгое применение 100-точечной системы
Даже при большом опыте эти данные всегда оцениваются. На этом этапе мы снова и снова испытываем положительные и отрицательные сюрпризы, особенно потому, что развитие зависит от соответствующих условий хранения. Понимание этого дает нам возможность сделать еще более точные заявления в будущем идеальным периодом для наилучшего наслаждения. Классификация производителей основана на репрезентативных оценках вина, которые винодельня достигла в долгосрочной перспективе. Это дает читателю с первого взгляда достоверную информацию о качестве соответствующего производителя.
Персональную 20-балльную шкалу выработал ежегодный европейский Vinum Magazine . Читатели Франции, Испании, Германии и Швейцарии, знают, что по версии «Винум Магазин» оценке 20 соответствует непревзойдённое вино, а с оценкой 14 вино будет вполне интересным.
Duemilavini (рейтинг Ассоциации сомелье Италии) оценивает все вина по пятибалльной системе подобно школьной с той лишь разницей, что «отличниками» считаются выдающиеся вина, «хорошисты» соответствуют отличным винам, а «троечниками» и «двоечниками» являются достаточно хорошие вина .
Классификация основана на многолетнем опыте, который наша вкусовая команда сделала с винами компании, в строгих условиях, которые применяются к виноделию. Для этой цели каждый классификатор должен иметь достаточное количество вин за последние годы. Компании, отмеченные таким образом, регулярно приглашаются на отправку своих вин.
Дегустация вин и вход в винный гид в основном бесплатны. Классификация производителей постоянно пересматривается в соответствии с представленными и отобранными винами. В то же время у нас есть немного больше времени с градациями, чем с восхождениями. Уже в подростковом возрасте он начал интенсивно заниматься темой вина, после того, как в конце 1980-х годов появилась возможность попробовать некоторые старые рислинги из винного погреба друга, он пробудил свою страсть к немецкому вину. В последующие десятилетия он смог получить глубокие знания в мире вина через свои путешествия и многочисленные дегустации.
Популярные винные критики разрабатывают собственные списки лучших вин. Южнокорейский винный критик Джинни Чо Ли (Jeannie Cho Lee) за 100 баллов принимает идеальное вино. 20-балльной шкалы придерживаются французские дегустаторы Мишель Беттан (Michel Bettane) и Тьери Дессов (Thierry Desseauve).
Читателям «Financial Time"s» хорошо известна еженедельная 20-балльная колонка Дженсис Робинсон (Jancis Robinson ), в которой исключительные вина оцениваются на 20 баллов, а Великие вина получают на балл ниже.
Ким Шрайбер родился в Нюрнберге и вырос в Среднем Франконическом Эккальенте-Ешенау. Люси Мельцер, любовь к вину была помещена в колыбель. Будучи полу-французом, она почти сразу же поддалась роду трав, а материнское молоко, и поэтому это было не так далеко от вина. Она обучила ее в известных ресторанах, от Занзибара в Зильте до Стэнджвирта в Китцбюэле, во многих винных турах и дегустациях. Поэтому логично, что страсть Люси к этому предмету привела ее к вине плюс.
Паркер - самый влиятельный критик в мире. Его суждение движет ценами самых дорогих вин. Теперь он продает части своей компании и передает главный редактор - мир вина ужасен. Вина были застрахованы на € 000. В секретном фургоне их отвезли на юг Испании, прямо из подвала сборщика из Северного Рейна-Вестфалии. Некоторые из вин были с шестидесятых годов, другие даже с 40-х годов, звезда вечера приходила с года. Частично они покупали коллекционер, когда они выходили на рынок, при высоких, но не непомерных ценах, отчасти менее 100 марок.
Не только профессиональные дегустаторы берутся составлять списки лучших вин. Каждый виноман-любитель может оставить своё мнение в веб-базе Cellar Tracker, винный рейтинг которой складывается из тысяч отзывов обычных пользователей интернета. На этом ресурсе исключительные вина оцениваются от 98 до 100 баллов, а от покупки вин ниже 60 баллов настоятельно рекомендовано воздерживаться.
То, что вино имеет высокое качество , производители уже знали при заполнении; что он когда-нибудь станет редким драгоценным делом. Он дал это вино 100 из 100 баллов. Если виноделы заполнят свои вина в ближайшие годы, они больше не смогут полагаться на них, чтобы получить помощь от американцев Западного побережья. На прошлой неделе Паркер объяснил, что он уйдет из ежедневного бизнеса и продаст большую часть своей публикации. То, что делают новые господа с их долями, неопределенно. Безусловно, вино-мир больше не будет прежним.
Паркерские точки - самая важная валюта в винной отрасли, влияние Паркерса на рынок вина огромно. Он был описан как «Ноль миллион долларов». Коллега Джансис Робинсон описал его как «самого опытного и заслуживающего доверия дегустатора в мире». Президент Франции Жак Ширак похвалил его как «самого известного и влиятельного винного критика французских вин в мире».
Команда единомышленников
Самый популярный в мире журнал о вине Wine Spectator
был основан в 1976 году в Сан-Диего морским офицером в отставке Робертом Моррисеем (Robert Morrisey).
Первый 12-страничный номер журнала был выпущен на дешёвой бумаге и выглядел первоапрельской шуткой, но информация, которая содержалась внутри, оказалась актуальной и интересной для многих читателей.
Адвокат Паркер видел себя в качестве потребительского адвоката, который предлагал своим читателям помощь в покупках вина. В настоящее время печатная версия информационного бюллетеня, опубликованная шесть раз в год, насчитывает около 10 000 покупателей по всему миру. Это сравнительно небольшое количество реальных читателей по сравнению с тем влиянием, которое его оценки имеют в отраслевых кругах. Даже самые престижные критики не влияют на цены, - говорит Вюрц. И это изменило цену.
Вино с 99 очками Паркера может удвоить его отпускную цену за одну ночь. Американский винный критик Роберт Паркер выступил на видео в прошлую пятницу. Однако он не превышает их. Паркерская переоценка вин ожидалась на рынке с большой неопределенностью. Это правда, что некоторые вина не всегда были в состоянии выполнить самые высокие ожидания, которые были им поставлены.
Через три года журнал перекупил издатель Марвин Шенкен (Marvin R. Shanken), который вот уже более трёх десятков лет является бессменным владельцем и главным редактором Wine Spectator.
С журналом Wine Spectator сотрудничают самые известные винные критики. Его авторами становятся самые значительные фигуры в эно-мире.
Одна из самых значительных фигур Wine Spectator - ведущий эксперт журнала Джеймс Саклинг (James Suckling). Саклинг начал сотрудничать с журналом ещё в 1981 году, а через семь лет стал главой его европейского бюро. Его многолетний опыт дегустатора сочетается со знаниями винодела и талантом писателя. Джеймс Саклинг совместно с главой журнала Марвином Шенкеном основали параллельный проект о табаке Cigar Aficionado. Саклинг посвятил журналу Wine Spectator 30 лет своей жизни и ушёл из него с тайным желанием начать делать своё вино.
Два неизвестных бутик-винных завода с идеальным классом
В преддверии выхода были озвучены слухи о том, что Паркер только поднимет девять вин в 100-балльном рейтинге на новой дегустации. На начальном этапе дегустации было десять вин, которые считались потенциальными кандидатами в 100 баллов. Оба выпускают только несколько тысяч бутылок.
Оба изначально были заметно ниже. Пять потенциальных высокопоставленных Шато: Мутон-Ротшильд, Лафит-Ротшильд, Л"Эглиз Клинет, Ла Мис-Хаут-Брион и, что удивительно, Аусон. Удивительный результат. На вопрос быстро ответить: рынок. Это соответствует цене перед публикацией в виде 100-точечного вина.
Старейший сотрудник журнала Харвей Стейман (Harvey Steiman) восхищает всех яркими эпитетами и красноречивыми описаниями вина. В 1993 году на дегустации в Лос-Анджелесе он дал такую характеристику вину: «это балансирование изобилия сладости и аромата на лезвии бритвы элегантности».
Со временем команда «Wine Spectator» стала сплочённым союзом единомышленников, влюблённых в вино и желающих воспитать хороший вкус у самой широкой публики.
Мнения разных рецензентов о том же вине в основном разные. Поэтому важно задействовать много разных источников. Роберт Паркер - самый влиятельный винный критик в мире. Цены на бордо и другие вина растут и падают из-за его оценки. Он уступил все территории, кроме Бордо, другим оценщикам. Это ставит вопрос о том, какой масштаб будет служить во всем мире для оценки вина в будущем. У большинства пьющих вина нет времени, чтобы составить мнение о винах мира. 100-балльная шкала полностью установлена и будет по-прежнему необходима.
Как и в киноиндустрии, в спорте и в кредитоспособности банков или стран, все так ценится и классифицируется, что даже менее непосредственное участие может сделать грубую картину. Тот факт, что качество винограда и, следовательно, вина подвержено винтажным колебаниям, больше всего осознает этот факт. Сочетание дождя, града, мороза, штормов и нерегулярной погоды во время сбора урожая привело к проблемам со зрелостью и заболеваниями винограда. Это не значит, что нас ждут дурные вина. Сегодня виноградные лозы и подвал гораздо более тщательно выработаны, и действительно плохие вина почти не найдены.
Журнал «Wine Spectator» учредил награду для рестораторов за лучшую винную карту. Первая премия «Grand Award» присуждается за широкий ассортимент вин с количеством наименований от полутора тысяч!
В 1996 году, через год после переезда редакции в Сан-Франциско, заработал персональный сайт winespectator.com.
Официальное признание журнал получил в 2008 году, когда американский информационно-исследовательский центр индустрии роскоши Luxury Institute объявил Wine Spectator лучшим изданием, публикующим материалы направления lifestyle.
Кроме того, менее хорошо оцененные классы имеют хорошие стороны. Во-первых, мы позволяем только средним годам оценивать качество курсов на высшем уровне. Во-вторых, вина из прохладных сортов с повышенной кислотностью и постным телом - отличные компаньоны для питья. В-третьих, в таких регионах, как Бордо, Бургундия или Тоскана, где качество винтажа напрямую влияет на цену лучших вин, на сделках можно охотиться на менее ликующих винтажах.
Тем не менее оценка с «точками Паркера» остается очень важной. Вина со всего мира оцениваются с использованием 100-точечной шкалы, при этом максимальным является 100 очков Паркера. С 100 точками вино считается идеальным, как вино века, и стоит почти каждой цены.
Сегодня стипендиальный фонд Wine Spectator с бюджетом около 11 миллионов долларов США поддерживает профессиональное образование в области вина и гастрономии.


ТОП-100
На страницах журнала Wine Spectator можно найти все новости мира виноделия, в каждом выпуске можно прочитать сотни обзоров лучших вин из самых разных уголков планеты, но главной заслугой Wine Spectator надо признать популярнейший рейтинг ТОП-100.
Американский винный критик Джеймс Солинг стал известен как главный редактор «Винного зрителя». Он считается одним из самых влиятельных винных критиков. Оценка вин основана на международно признанной 100-балльной шкале. Она написала многочисленные винные книги, такие как «Оксфордский винник» и «Мастер вина». Счет 20 очков.
Вина из 16 очков «выделяются из толпы», причем 17 очков «отлично», причем 18 очков «несколько более чем отлично», с 19 очками «большой класс», с 20 очками «очень особенным». Эксповина является самым важным испытанием международного винного предложения на швейцарском рынке.
Свою первую винную дегустацию Wine Spectator провёл в 1980 году, но лишь через восемь лет после этого события был составлен первый ежегодный список вин «лучшая сотня вин 1988 года». С началом ежегодных публикаций Wine Spectator Top-100 и без того высокий интерес к журналу возрос многократно.
Рейтинг вин ТОП-100 формируется на основании экспертных оценок профессионалов, каждый из которых является специалистом в определённой винодельческой области. Винные образцы закупаются в торговых американских сетях, приобретаются у производителей и их посредников.
Жюри присуждает премии «Большое золото», «Золото» и «Серебряный». «Декантер» - один из самых важных винных журналов. Первоначально из Англии «Графин» теперь читается более чем в девяноста странах, причем более половины читателей за пределами Англии. Он рассчитан на две шкалы - с 20 очками и с 100 очками.
Он оценивается по 100-балльной схеме Роберта Паркера. Джеймс Холлидей - австралийский винный критик и автор вина. В «Австралийском винодельце», опубликованном Джеймсом Холлидеем, вина оцениваются по международно признанной 100-балльной шкале. Конкурс открыт для всех органических вин, которые соответствуют применимым европейским нормам органического земледелия. Международное жюри экспертов по винам предоставляет «золото», «серебро» и «бронза». Сегодня этот случай является одной из самых крупных и признанных винных наград во всем мире.
Редакторы журнала выбирают лучшие вина по 100-балльной шкале, обращая внимание не только на качество самого напитка, но и на его доступность для покупателей по стоимости и наличию в продаже в достаточном количестве. Слишком дорогие вина или коллекционные экземпляры, выпущенные ограниченной серией, практически не имеют возможности пробиться в лидирующую десятку. В рейтинге сотни лучших вин практически отсутствуют Великие бургундские вина или вина исторических бордоских поместий. Средняя цена вин в ТОП-100-2013 составила 51 доллар США при среднем рейтинге 93 балла.
Жюри награждает «Великое золото», «Золото» и «Серебро». Шведский Ричард Юхлин считается экспертом шампанского № 1 по всему миру. Его руководство по шампанскому расположено почти в каждом погребе в регионе и считается стандартом для всех любителей шампанского. Вино основано на всемирно признанной 100-балльной шкале. Тем не менее, шкала у Ричарда Юхлина по сравнению с довольно бесплатными оценками, мы переместили Роберта Паркера примерно на 10 очков. Только 1 шампанское имеет по 100 очков. Также очень хорошие вина с 80 очками.
Независимые эксперты по винам оценивают различные вина из всех винных регионов. С середины 70-х годов инновационная и объективная оценка вина в соответствии с паркером в настоящее время определяет международную торговлю вином. Критики Роберта Паркера предпочитают фруктовые и плотные вина, так что критерии оценки, такие как элегантность и сложность, менее важны которые могут быть отнесены к диапазону 90 или даже 95 баллов. Схема оценки Роберта Паркера. От 50 до 69 баллов: от низкого до низкого уровня.
Немаловажным показателем, влияющим на выбор эксперта, является эмоциональная составляющая. Самобытные, новаторские, уникальные по вкусу экземпляры имеют большой шанс выйти на первые позиции рейтинга.
Магия верхней строчки
За четверть века многое изменилось. Если в 1988 году к оценке предлагалось около трёх тысяч позиций вин, то в 2013 году количество дегустируемых наименований увеличилось почти в семь раз! За последние два десятка лет в списки лучших попадали вина 18 стран.
По спискам лучшей сотни хорошо заметно, что винам США уделяется особое внимание, поскольку журнал Wine Spectator ориентируется на продукцию американского рынка. Вина Франции по частоте упоминания находятся на втором месте и составляют почти треть списка, а итальянская продукция занимает уверенное третье место.
Анализируя вина первой десятки, можно отметить постоянное лидерство калифорнийских хозяйств Долины Напа и Сономы.
За последнее десятилетие в десятку лучших попадали вина Франции, США (почти по 30 раз каждая из этих стран) и Италии (19 раз). Следом идут австралийские, чилийские и португальские вина. Вина Аргентины и Германии за последнее десятилетие побывали в лучшей десятке по одному разу.
Если посмотреть на французские вина лучшей десятки, то можно с удивлением констатировать, что в любимчиках редакторов Wine Spectator оказываются экземпляры из Долины Роны, воспетые Паркером. Они опережают даже идеальную классику Бордо. По результатам лучшей сотни можно заметить трепетную любовь американцев к сладким упоительным Сотернам.
Среди итальянских вин лидирует продукция Тосканы. Явное предпочтение эксперты журнала отдают Брунелло ди Монтальчино и пьемонтскому Бароло. Абсолютным лидером с четырёхкратным попаданием в ТОП-10 стал австралийский Шираз Бэллас Гарден (Bella’s Garden) из Долины Баросса.
Наибольший интерес вызывает первая строчка рейтинга Wine Spectator Top-100. Но определить одного чемпиона - задача практически невыполнимая, принимая во внимание тот факт, что на планете ежесезонно выпускаются десятки тысяч разных вин, и почти все они попадают на полки американских магазинов.
Относительная субъективность оценки тоже исключает выбор одного единственного вина. Тем не менее, за последнее десятилетие вином номер один шесть раз объявлялось вино американских производителей, дважды - французское вино, по одному разу - вина из Италии и Чили.
Рейтинг Wine Spectator Top-100 отражает американский вкус. Любовь к сочным сильным винам выражается в процентах сухой статистики. За последние 10 лет 85% продукции виноделия приходится на красные вина, а пристрастие к белым и сладким винам делится практически пополам с небольшим отрывом белых. На игристые вина приходится всего один процент.
Популярность лучшей сотни среди читателей журнала Wine Spectator частично объясняется живой и интригующей подачей материала. Сотрудники журнала устраивают из этого события настоящее шоу, подобное вручению Оскара. Задолго до появления публикации рейтинговых списков начинается обратный отсчёт времени. Имена победителей до последнего мгновения остаются тайной. О степени славы рейтинга ТОП-100 говорит недавний инцидент, когда хакер взломал сайт и выложил раньше времени десятку лучших вин.


И любители вина, и виноделы из разных регионов Старого и Нового Света каждый ноябрь волнуются в ожидании публикации блистательного рейтинга Wine Spectator Top-100.
Практически любому человеку для общего развития желательно научиться нескольким вещам. Среди прочего не повредить и умение различать самые известные вина и подбирать наиболее подходящий для конкретного события напиток. Чтобы, посещая, к примеру, ресторан "Времена года" , то ли просто поужинать, или планируя торжественное мероприятие, не растеряться при выборе вина. Этот рейтинг наиболее популярных вин, был составлен редакторами портала AskMen.com после посещения Монреальской выставки алкогольных напитков.
ТОП 5 наиболее популярных вин в мире.
1) Каберне Совиньон - красное вино родом из Бордо, Франция.
Этот напиток иногда называют «Королем красных вин». В зависимости от возраста, Каберне Совиньон слегка меняет и вкус, и запах. Так, вино выдержкой от 10 до 15 лет обладает дубовым ароматом, в котором можно различить оттенки кофейных, табачных, шоколадных запахов. Напиток помладше - 3-7 лет - пахнет фруктами. Ценители считают, что такое вино сочетает в себе клюквенные, малиновые и сливовые оттенки вкуса.
Кстати, Каберне Совиньон впервые появилось в 17 веке. И тогда, и сейчас его делают из винограда сортов Каберне Фран и Совиньон Блан (отсюда и итоговое название). Продают это вино практически в любой точке мира - от Канады до Австралии, от Чили до Италии. Подают же его обычно с мясными блюдами и десертами из шоколада.
2) Шираз
Шираз - еще один сорт красного вина. Его делают из винограда «Сира». Шираз часто называют вином мужчин - надежным, ароматным, с ярко выраженным вкусом.
Родом Шираз из Франции (где его, кстати, по-прежнему именуют «Сира», как и сорт винограда). Однако широкую известность этот напиток получил отчасти благодаря Восточной Австралии, где активно начали заниматься его изготовлением и распространением. Интересно, что вкус вина Шираз очень сильно зависит не только от марки и производителя, но и от климата, почвы и прочих условий, в которых рос виноград. В этом особый шик и прелесть этого напитка - он очень разный.
Шираз подают с красным мясом и сырами. Он прекрасно сочетается также с блюдами из дичи.
3) Гевюрцтраминер
Легкое белое вино с прекрасным долгим послевкусием - это, конечно, Гевюрцтраминер, которые готовится из одноименного сорта винограда. Считается, что лучшие представители этого напитка получаются из северных виноградников - говорят, Гевюрцтаминер любит холод.
Правда, растет этот виноград везде - и в Канаде, и в Италии, и во Франции.
Гевюрцтаминер относят к полусухим винам. Оно сладкое, полное цветочных запахов и фруктовых нот. В это вино часто добавляют ароматы специй - например, имбирь.
Его подают обычно как аперитив. Неплохо Гевюрцтаминер подойдет к блюдам из морепродуктов или жирной пище.
4) Шардоне
Одно из самых любимых американских вин - это Шардоне. Оно отличается демократичной стоимостью и разнообразием марок, изготавливающих этот напиток. Делают его из одноименного винограда, который, кстати, растет почти в любых условиях и считается весьма неприхотливым растением.
Интересно, что очень многие известные винодельни начинали именно с Шардоне. Это помогло вину быстро завоевать популярность и распространиться по всему миру. А вот родилось Шардоне, предположительно, в Бургундии - одной из провинций Франции.
На сегодня этот сорт вина - один из наиболее дешевых и узнаваемых как в Америке, так и в Европе.
Подают Шардоне к блюдам из птицы, рыбы и свинины.
5) Мерло
Менее терпкое и менее кислое, чем Каберне Совиньон, Мерло завоевало славу «женского напитка». Родом оно тоже из Бордо, но получило распространение значительно позже, чем его собрат.
Мерло - красное вино с фруктовыми нотками в аромате и вкусе: черники, ежевики, ванили, сливы.
Предпочтительнее всего подавать этот напиток с мясными блюдами. Например, его предлагают к сосискам, жаркому, телятине, баранине, бобовым.
Получение частных данных не всегда означает взлом - иногда они опубликованы в общем доступе. Знание настроек Google и немного смекалки позволят найти массу интересного - от номеров кредиток до документов ФБР.
WARNING
Вся информация предоставлена исключительно в ознакомительных целях. Ни редакция, ни автор не несут ответственности за любой возможный вред, причиненный материалами данной статьи.К интернету сегодня подключают всё подряд, мало заботясь об ограничении доступа. Поэтому многие приватные данные становятся добычей поисковиков. Роботы-«пауки» уже не ограничиваются веб-страницами, а индексируют весь доступный в Сети контент и постоянно добавляют в свои базы не предназначенную для разглашения информацию. Узнать эти секреты просто - нужно лишь знать, как именно спросить о них.
Ищем файлы
В умелых руках Google быстро найдет все, что плохо лежит в Сети, - например, личную информацию и файлы для служебного использования. Их частенько прячут, как ключ под половиком: настоящих ограничений доступа нет, данные просто лежат на задворках сайта, куда не ведут ссылки. Стандартный веб-интерфейс Google предоставляет лишь базовые настройки расширенного поиска, но даже их будет достаточно.
Ограничить поиск по файлам определенного вида в Google можно с помощью двух операторов: filetype и ext . Первый задает формат, который поисковик определил по заголовку файла, второй - расширение файла, независимо от его внутреннего содержимого. При поиске в обоих случаях нужно указывать лишь расширение. Изначально оператор ext было удобно использовать в тех случаях, когда специфические признаки формата у файла отсутствовали (например, для поиска конфигурационных файлов ini и cfg, внутри которых может быть все что угодно). Сейчас алгоритмы Google изменились, и видимой разницы между операторами нет - результаты в большинстве случаев выходят одинаковые.

Фильтруем выдачу
По умолчанию слова и вообще любые введенные символы Google ищет по всем файлам на проиндексированных страницах. Ограничить область поиска можно по домену верхнего уровня, конкретному сайту или по месту расположения искомой последовательности в самих файлах. Для первых двух вариантов используется оператор site, после которого вводится имя домена или выбранного сайта. В третьем случае целый набор операторов позволяет искать информацию в служебных полях и метаданных. Например, allinurl отыщет заданное в теле самих ссылок, allinanchor - в тексте, снабженном тегом , allintitle - в заголовках страниц, allintext - в теле страниц.
Для каждого оператора есть облегченная версия с более коротким названием (без приставки all). Разница в том, что allinurl отыщет ссылки со всеми словами, а inurl - только с первым из них. Второе и последующие слова из запроса могут встречаться на веб-страницах где угодно. Оператор inurl тоже имеет отличия от другого схожего по смыслу - site . Первый также позволяет находить любую последовательность символов в ссылке на искомый документ (например, /cgi-bin/), что широко используется для поиска компонентов с известными уязвимостями.
Попробуем на практике. Берем фильтр allintext и делаем так, чтобы запрос выдал список номеров и проверочных кодов кредиток, срок действия которых истечет только через два года (или когда их владельцам надоест кормить всех подряд).
Allintext: card number expiration date /2017 cvv

Когда читаешь в новостях, что юный хакер «взломал серверы» Пентагона или NASA, украв секретные сведения, то в большинстве случаев речь идет именно о такой элементарной технике использования Google. Предположим, нас интересует список сотрудников NASA и их контактные данные. Наверняка такой перечень есть в электронном виде. Для удобства или по недосмотру он может лежать и на самом сайте организации. Логично, что в этом случае на него не будет ссылок, поскольку предназначен он для внутреннего использования. Какие слова могут быть в таком файле? Как минимум - поле «адрес». Проверить все эти предположения проще простого.

Inurl:nasa.gov filetype:xlsx "address"

Пользуемся бюрократией
Подобные находки - приятная мелочь. По-настоящему же солидный улов обеспечивает более детальное знание операторов Google для веб-мастеров, самой Сети и особенностей структуры искомого. Зная детали, можно легко отфильтровать выдачу и уточнить свойства нужных файлов, чтобы в остатке получить действительно ценные данные. Забавно, что здесь на помощь приходит бюрократия. Она плодит типовые формулировки, по которым удобно искать случайно просочившиеся в Сеть секретные сведения.
Например, обязательный в канцелярии министерства обороны США штамп Distribution statement означает стандартизированные ограничения на распространение документа. Литерой A отмечаются публичные релизы, в которых нет ничего секретного; B - предназначенные только для внутреннего использования, C - строго конфиденциальные и так далее до F. Отдельно стоит литера X, которой отмечены особо ценные сведения, представляющие государственную тайну высшего уровня. Пускай такие документы ищут те, кому это положено делать по долгу службы, а мы ограничимся файлами с литерой С. Согласно директиве DoDI 5230.24, такая маркировка присваивается документам, содержащим описание критически важных технологий, попадающих под экспортный контроль. Обнаружить столь тщательно охраняемые сведения можно на сайтах в домене верхнего уровня.mil, выделенного для армии США.
"DISTRIBUTION STATEMENT C" inurl:navy.mil

Очень удобно, что в домене.mil собраны только сайты из ведомства МО США и его контрактных организаций. Поисковая выдача с ограничением по домену получается исключительно чистой, а заголовки - говорящими сами за себя. Искать подобным образом российские секреты практически бесполезно: в доменах.ru и.рф царит хаос, да и названия многих систем вооружения звучат как ботанические (ПП «Кипарис», САУ «Акация») или вовсе сказочные (ТОС «Буратино»).

Внимательно изучив любой документ с сайта в домене.mil, можно увидеть и другие маркеры для уточнения поиска. Например, отсылку к экспортным ограничениям «Sec 2751», по которой также удобно искать интересную техническую информацию. Время от времени ее изымают с официальных сайтов, где она однажды засветилась, поэтому, если в поисковой выдаче не удается перейти по интересной ссылке, воспользуйся кешем Гугла (оператор cache) или сайтом Internet Archive.
Забираемся в облака
Помимо случайно рассекреченных документов правительственных ведомств, в кеше Гугла временами всплывают ссылки на личные файлы из Dropbox и других сервисов хранения данных, которые создают «приватные» ссылки на публично опубликованные данные. С альтернативными и самодельными сервисами еще хуже. Например, следующий запрос находит данные всех клиентов Verizon, у которых на роутере установлен и активно используется FTP-сервер.
Allinurl:ftp:// verizon.net
Таких умников сейчас нашлось больше сорока тысяч, а весной 2015-го их было на порядок больше. Вместо Verizon.net можно подставить имя любого известного провайдера, и чем он будет известнее, тем крупнее может быть улов. Через встроенный FTP-сервер видно файлы на подключенном к маршрутизатору внешнем накопителе. Обычно это NAS для удаленной работы, персональное облако или какая-нибудь пиринговая качалка файлов. Все содержимое таких носителей оказывается проиндексировано Google и другими поисковиками, поэтому получить доступ к хранящимся на внешних дисках файлам можно по прямой ссылке.

Подсматриваем конфиги
До повальной миграции в облака в качестве удаленных хранилищ рулили простые FTP-серверы, в которых тоже хватало уязвимостей. Многие из них актуальны до сих пор. Например, у популярной программы WS_FTP Professional данные о конфигурации, пользовательских аккаунтах и паролях хранятся в файле ws_ftp.ini . Его просто найти и прочитать, поскольку все записи сохраняются в текстовом формате, а пароли шифруются алгоритмом Triple DES после минимальной обфускации. В большинстве версий достаточно просто отбросить первый байт.

Расшифровать такие пароли легко с помощью утилиты WS_FTP Password Decryptor или бесплатного веб-сервиса .

Говоря о взломе произвольного сайта, обычно подразумевают получение пароля из логов и бэкапов конфигурационных файлов CMS или приложений для электронной коммерции. Если знаешь их типовую структуру, то легко сможешь указать ключевые слова. Строки, подобные встречающимся в ws_ftp.ini , крайне распространены. Например, в Drupal и PrestaShop обязательно есть идентификатор пользователя (UID) и соответствующий ему пароль (pwd), а хранится вся информация в файлах с расширением.inc. Искать их можно следующим образом:
"pwd=" "UID=" ext:inc
Раскрываем пароли от СУБД
В конфигурационных файлах SQL-серверов имена и адреса электронной почты пользователей хранятся в открытом виде, а вместо паролей записаны их хеши MD5. Расшифровать их, строго говоря, невозможно, однако можно найти соответствие среди известных пар хеш - пароль.

До сих пор встречаются СУБД, в которых не используется даже хеширование паролей. Конфигурационные файлы любой из них можно просто посмотреть в браузере.
Intext:DB_PASSWORD filetype:env

С появлением на серверах Windows место конфигурационных файлов отчасти занял реестр. Искать по его веткам можно точно таким же образом, используя reg в качестве типа файла. Например, вот так:
Filetype:reg HKEY_CURRENT_USER "Password"=
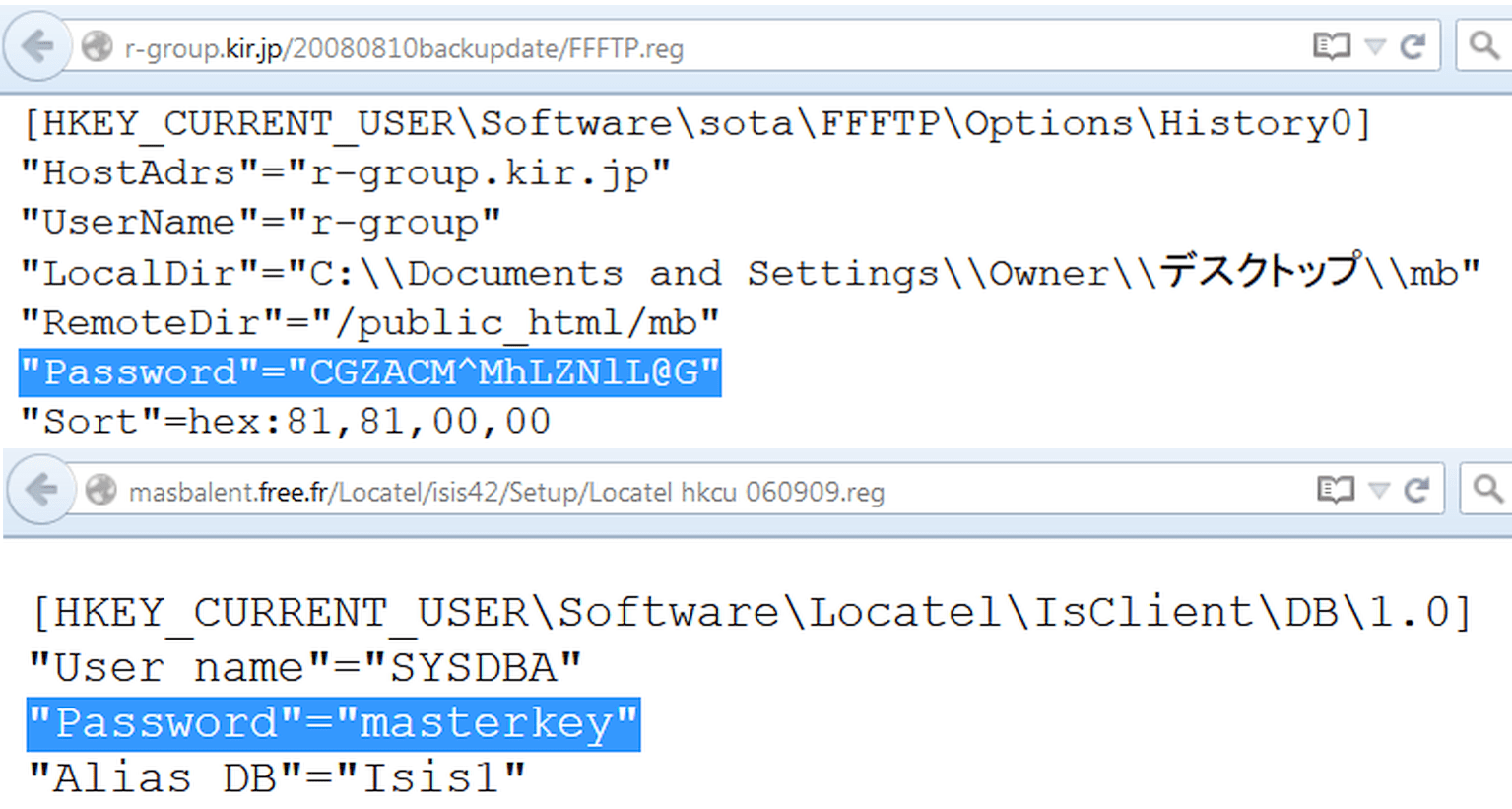
Не забываем про очевидное
Иногда добраться до закрытой информации удается с помощью случайно открытых и попавших в поле зрения Google данных. Идеальный вариант - найти список паролей в каком-нибудь распространенном формате. Хранить сведения аккаунтов в текстовом файле, документе Word или электронной таблице Excel могут только отчаянные люди, но как раз их всегда хватает.
Filetype:xls inurl:password

С одной стороны, есть масса средств для предотвращения подобных инцидентов. Необходимо указывать адекватные права доступа в htaccess, патчить CMS, не использовать левые скрипты и закрывать прочие дыры. Существует также файл со списком исключений robots.txt, запрещающий поисковикам индексировать указанные в нем файлы и каталоги. С другой стороны, если структура robots.txt на каком-то сервере отличается от стандартной, то сразу становится видно, что на нем пытаются скрыть.

Список каталогов и файлов на любом сайте предваряется стандартной надписью index of. Поскольку для служебных целей она должна встречаться в заголовке, то имеет смысл ограничить ее поиск оператором intitle . Интересные вещи находятся в каталогах /admin/, /personal/, /etc/ и даже /secret/.

Следим за обновлениями
Актуальность тут крайне важна: старые уязвимости закрывают очень медленно, но Google и его поисковая выдача меняются постоянно. Есть разница даже между фильтром «за последнюю секунду» (&tbs=qdr:s в конце урла запроса) и «в реальном времени» (&tbs=qdr:1).
Временной интервал даты последнего обновления файла у Google тоже указывается неявно. Через графический веб-интерфейс можно выбрать один из типовых периодов (час, день, неделя и так далее) либо задать диапазон дат, но такой способ не годится для автоматизации.
По виду адресной строки можно догадаться только о способе ограничить вывод результатов с помощью конструкции &tbs=qdr: . Буква y после нее задает лимит в один год (&tbs=qdr:y), m показывает результаты за последний месяц, w - за неделю, d - за прошедший день, h - за последний час, n - за минуту, а s - за секунду. Самые свежие результаты, только что ставшие известными Google, находится при помощи фильтра &tbs=qdr:1 .
Если требуется написать хитрый скрипт, то будет полезно знать, что диапазон дат задается в Google в юлианском формате через оператор daterange . Например, вот так можно найти список документов PDF со словом confidential, загруженных c 1 января по 1 июля 2015 года.
Confidential filetype:pdf daterange:2457024-2457205
Диапазон указывается в формате юлианских дат без учета дробной части. Переводить их вручную с григорианского календаря неудобно. Проще воспользоваться конвертером дат .
Таргетируемся и снова фильтруем
Помимо указания дополнительных операторов в поисковом запросе их можно отправлять прямо в теле ссылки. Например, уточнению filetype:pdf соответствует конструкция as_filetype=pdf . Таким образом удобно задавать любые уточнения. Допустим, выдача результатов только из Республики Гондурас задается добавлением в поисковый URL конструкции cr=countryHN , а только из города Бобруйск - gcs=Bobruisk . В разделе для разработчиков можно найти полный список .
Средства автоматизации Google призваны облегчить жизнь, но часто добавляют проблем. Например, по IP пользователя через WHOIS определяется его город. На основании этой информации в Google не только балансируется нагрузка между серверами, но и меняются результаты поисковой выдачи. В зависимости от региона при одном и том же запросе на первую страницу попадут разные результаты, а часть из них может вовсе оказаться скрытой. Почувствовать себя космополитом и искать информацию из любой страны поможет ее двухбуквенный код после директивы gl=country . Например, код Нидерландов - NL, а Ватикану и Северной Корее в Google свой код не положен.
Часто поисковая выдача оказывается замусоренной даже после использования нескольких продвинутых фильтров. В таком случае легко уточнить запрос, добавив к нему несколько слов-исключений (перед каждым из них ставится знак минус). Например, со словом Personal часто употребляются banking , names и tutorial . Поэтому более чистые поисковые результаты покажет не хрестоматийный пример запроса, а уточненный:
Intitle:"Index of /Personal/" -names -tutorial -banking
Пример напоследок
Искушенный хакер отличается тем, что обеспечивает себя всем необходимым самостоятельно. Например, VPN - штука удобная, но либо дорогая, либо временная и с ограничениями. Оформлять подписку для себя одного слишком накладно. Хорошо, что есть групповые подписки, а с помощью Google легко стать частью какой-нибудь группы. Для этого достаточно найти файл конфигурации Cisco VPN, у которого довольно нестандартное расширение PCF и узнаваемый путь: Program Files\Cisco Systems\VPN Client\Profiles . Один запрос, и ты вливаешься, к примеру, в дружный коллектив Боннского университета.
Filetype:pcf vpn OR Group

INFO
Google находит конфигурационные файлы с паролями, но многие из них записаны в зашифрованном виде или заменены хешами. Если видишь строки фиксированной длины, то сразу ищи сервис расшифровки.Пароли хранятся в зашифрованном виде, но Морис Массар уже написал программу для их расшифровки и предоставляет ее бесплатно через thecampusgeeks.com .
При помощи Google выполняются сотни разных типов атак и тестов на проникновение. Есть множество вариантов, затрагивающих популярные программы, основные форматы баз данных, многочисленные уязвимости PHP, облаков и так далее. Если точно представлять то, что ищешь, это сильно упростит получение нужной информации (особенно той, которую не планировали делать всеобщим достоянием). Не Shodan единый питает интересными идеями, но всякая база проиндексированных сетевых ресурсов!
Sony Xperia Z, Z1, Z2, Z3, Z5 — как не запутаться, перечисляя модификации смартфонов, выпущенные за последние 3 года? И это не считая версий вроде Compact, Ultra или Premium, которые тоже существуют в линейке японской марки. Чтобы жить было интереснее и
Любой пользователь интернета, использует возможности интернета по своим нуждам, кому-то он нужен для развлечений, кому-то для связи с друзьями, родными и близкими людьми, а кто-то приходит сюда для того чтобы зарабатывать, а возможно и для того, чтобы вес
Добрый день.Аккумуляторная батарея есть абсолютно в каждом ноутбуке (без нее немыслимо представить себе мобильное устройство).Случается иногда так, что она перестает заряжаться: и вроде бы ноутбук подключен к сети, и все светодиоды на корпусе моргают, да

 — как зарабатывают в ВК, Инстаграме, Ютубе, Фейсбуке и других социальных сетях")




